氮是微生物繁殖的必要元素,但也是引发水体富营养化的元素之一〔1 〕 。出水总氮(TN)是污水排放的重要指标之一,当出水TN检测结果不达标时,污水厂会采取应急措施,通过调整某个工艺段的工艺参数来解决问题。因此,根据实时进水水质情况判断未来出水TN是否存在超标可能并提前对工艺参数进行调整,对污水处理系统的优化具有重要意义。
在污水水质预测创建模型方面,众多学者从污水处理过程机理和数据驱动方式去构建模型。O. S. DJANDJA等〔2 〕 提出一种根据生化反应温度与原料中元素含量关系的前馈神经网络氮含量预测模型。乔俊飞等〔3 〕 采用一种基于递归径向基(RBF)神经网络算法的氨氮软测量方法。尽管神经网络算法在预测领域有着不错的性能表现,但也存在一定局限性,如收敛速度慢、易陷入局部极值、过度拟合等〔4 〕 。
与神经网络算法相比,支持向量回归机(SVR)具有训练时间短、泛化能力强、预测精度高的优点,并且克服了神经网络算法在小样本、非线性问题中的重复性差、过度拟合等不足,更适用于预测研究〔5 -8 〕 。然而,SVR模型构建的关键是解决核参数σ 和惩罚因子c 的最优取值问题,初期算法的参数选取多依赖于主观经验,缺乏严谨的数学依据。本研究通过引入基于高斯函数递减步长的萤火虫算法(GNFA)对SVR参数进行优化,可有效提高模型的预测准确度。
1 基本原理
1.1 支持向量回归机
支持向量回归机(SVR)是一种监督性机器学习算法,是在支持向量机(SVM)理论基础上延伸出的一种对回归分析问题的应用模型。SVR通过引入不敏感损失系数ε 让所有的样本点与超平面距离和最小,得到一个最佳条状区域(2ε 宽度),以达到期望风险最小的目的〔9 〕 。
给定n 个训练样本D = ( x i , y i ) | i = 1,2 , … , n x i ∈ R n , y i ∈ R n x i y i 式(1)。其中,ω 是权向量;φ ( x ) b 为偏置值。
f ( x ) = ω T φ ( x ) + b (1)
引入不敏感损失系数ε 与惩罚因子c ,y i f ( x i ) y i f ( x i ) ε 时计算损失;反之则认为预测正确,不计算损失〔10 〕 。不敏感损失系数ε 对模型影响较小,选取0.15即可。根据最小结构风险原则,建立约束条件〔式(2)〕与目标函数〔式(3)〕。
L [ f ( x i ) , y i , ε ] = 0 | y i - f ( x i ) | ≤ ε | y i - f ( x i ) | - ε | y i - f ( x i ) | > ε (2)
m i n ω , b J ( ω , b ) = 1 2 | | ω | | 2 + c ∑ i = 1 n | y i - f ( x i ) | (3)
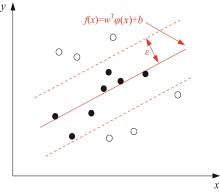
图1 为SVR的示意图,黑色实心的数据点表示模型预测结果是有效的。
图1
图1
支持向量回归示意
Fig. 1
Support vector regression diagram
惩罚因子c 的取值影响模型的结构风险,取值过大,结构风险越大,模型容易出现过拟合;取值过小,模型会过于简单化,易出现欠拟合问题〔11 〕 。
引入松弛变量ξ i ξ i * 式(4)〕。
m i n ω , b 1 2 ω 2 + c ∑ i = 1 m ( ξ i + ξ i * ) s . t . y i - ω φ ( x ) - b ≤ ε + ξ i - y i + ω φ ( x ) + b ≤ ε + ξ i * ξ i ≥ 0 , ξ i * ≥ 0 (4)
引入拉格朗日乘子α α * 式(4)变换为对偶形式〔式(5)〕。式中,K ( x i , x j ) = φ ( x i ) φ ( x j )
m a x α , α * ∑ i = 1 n y i ( α i - α i * ) - ε ∑ i = 1 n ( α i - α i * ) - 1 2 ∑ i = 1 n ∑ j = 1 n ( α i - α i * ) ( α j - α j * ) K ( x i , x j ) s . t . ∑ i = 1 n ( α i - α i * ) = 0 (5)
根据式(5)的函数关系式可求出α α * 式(6)。
f ( x ) = ∑ i = 1 m ( α i - α i * ) K ( x i , x j ) + b (6)
映射时发现,当变量增多时,映射到高维空间的维度呈指数增长,导致计算难度骤增;而引入核函数可使低维计算结果等效于高维。核函数根据需要选取,研究中选用径向核函数,表达式见式(7)。σ 为径向核函数的核参数,其取值大小也会影响模型效果,取值过小会导致模型的泛化能力减弱,取值过大会令模型出现过拟合现象。
K ( x i , x j ) = e x p [ - ( x i - x j ) 2 / 2 σ 2 ] (7)
综上,SVR模型构建的关键是解决核参数σ 和惩罚因子c 的最优取值问题。
1.2 改进萤火虫算法
萤火虫算法(FA)是一种启发式算法,是根据自然界中萤火虫的发光行为提出的〔12 〕 。在FA中,空间里的每一个解就好比萤火虫种群里的每一只萤火虫,空间里的初始解可以理解为萤火虫种群的初始位置,萤火虫通过个体之间的吸引进行移动,完成位置的更新,即完成解的更新〔13 〕 。
搜索过程涉及到萤火虫的发光亮度和相互吸引度〔14 〕 ,这2个参数都与萤火虫之间的距离成反比,这与自然现象中光在空间传播时被传播介质吸收而逐渐衰减的特性一致。
I r = I 0 e - γ r i j 2 (8)
式中,I r r i j i j r i j = | | X i - X j | | γ 的改变可以理解为传播介质的改变,可设置为常数;当萤火虫个体与光源的距离逐渐趋近于0时,萤火虫的发光亮度最为明亮,即为I 0 〔15 〕 。
萤火虫的吸引度β 式(9),与萤火虫发光强度同理,当萤火虫个体与光源的距离逐渐趋近于0时,吸引度最大,即为β 0 〔16 〕 。
β = β 0 e - γ r i j 2 (9)
萤火虫i j 式(10)决定。
X i ' = X i + β ( X j - X i ) + α ( r a n d - 0.5 ) (10)
式中,X i ' α ( r a n d - 0.5 ) α r a n d 〔17 〕 。
在文献〔18 〕中,优化粒子群算法引入了线性递减权重。受该思路启发,不妨将萤火虫的步长进行线性递减优化,定义该种改进算法为线性递减步长萤火虫算法(LFA),具体步长变化表达式见式(11)。
α = α m a x - α m a x - α m i n T m a x × t (11)
式中,α α m a x α m i n t T m a x
因为FA算法在实际问题的寻优过程中是复杂非线性的,所以步长也呈动态非线性变化预计会出现较好的寻优结果。结合高斯函数分布的特性,猜想当步长的随机变化呈正态分布时,能够提高算法的寻优精度。因此,根据高斯函数分布特性,把相应的步长参数带入步长变化表达式,实现对步长α 式(12)。
α ( t ) = ( α m a x - α m i n ) e x p - t 2 k T 2 + α m i n (12)
式中,常数k 可以影响曲线的凹凸程度,即曲线的变化率可通过k 进行调整。
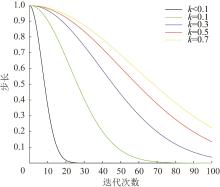
以步长取值范围为0~1、最大迭代次数为100时为例,图2 给出了不同k 值对应步长的变化曲线。
图2
图2
k 取不同值时步长的变化
Fig. 2
Change of step with different k
由图2 可看出,当k ≤0.1时,步长过早收敛于0,导致寻优效果过于局限;当k ≥0.3时,步长在整个迭代过程中的变化趋势较为平缓,不利于算法收敛。所以本研究中k 取0.2,高斯函数递减步长的萤火虫算法(GNFA)位置更新表达式见式(13)。
X i ' = X i + β ( X j - X i ) + α ( r a n d - 0.5 ) α = ( α m a x - α m i n ) e x p - t 2 k T 2 + α m i n , k = 0.2 (13)
2 GNFA算法性能测试
为验证改进算法的性能,分别将FA、LFA与提出的GNFA进行比较。选择Sphere函数和Ackley函数作为测试算法性能的函数,Sphere函数多用来检验算法的收敛速度和精度,Ackley函数可以测试算法的局部寻优能力。这2个函数是最常见的测试函数,被广泛应用在算法测试性能实验中〔19 〕 。
在仿真环境中,萤火虫步长改进优化算法的具体参数设置为:萤火虫数目M =20,光强吸收系数γ =1.0,初始吸引度β 0 α m a x α m i n T =500,α Th 设置为10-3 。而FA算法步长设置为0.4,其他参数和改进算法设置一致。测试函数的搜索范围、期望目标值、搜索空间维数及函数类型等见表1 。
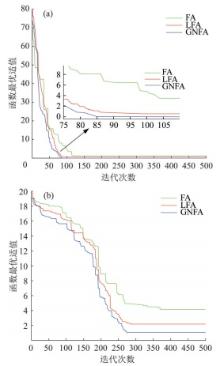
测试函数的优化结果见表2 ,平均最优值随迭代次数增加的变化曲线见图3 。
图3
图3
Sphere函数(a)和Ackley函数(b)收敛曲线
Fig. 3
Convergence curves of Sphere function(a) and Ackley function (b)
从表2 的优化结果可看出,相比LFA与标准FA算法,GNFA算法综合表现更佳,说明当采用高斯非线性递减方式改进步长策略时,萤火虫个体寻优性能强,且算法执行时间也得到优化。
从图3 可看出,3种算法对单峰值Sphere函数的优化结果在寻优精度上相差不大,但GNFA收敛速度快于其他2种算法。3种算法对多峰值Ackley函数的优化结果说明,在迭代后期,标准FA算法定值步长容易导致算法陷入局部最优;而LFA算法的性能表现介于其他2种算法。虽然线性递减改进步长策略并非最好的优化方式,但也说明了步长α
3 基于GNFA-SVR的TN软测量建模
3.1 模型数据选取与处理
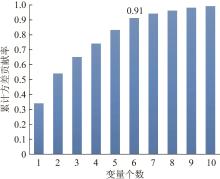
如果进水水质组分全部被选作特征向量,其中部分特征变量存在弱相关性的问题往往会被忽视,导致维度过高,模型的计算时间和计算难度增加,不利于模型预测结果分析。主成分分析(PCA)是一种对高维度特征数据降维的统计分析法,有利于确定特征变量维数。图4 为使用PCA对数据特征变量进行降维分析的相关度,当选取6个特征变量时,总体的累计方差贡献率已经达到了90%。故本研究选取6个特征变量:进水COD、TN、NH4 + -N、温度(T )、浊度(SS)、DO,并以出水总氮(TN)作为模型输出。
图4
图4
累计方差贡献率
Fig. 4
Cumulative variance contribution rate
从某污水厂2021年6月至9月水质信息库共获取657组样本数据,部分采集数据见表3 。其中200组数据作为测试数据用于检验模型性能,457组数据作为训练集用于预测模型训练。
样本数据通常不直接使用,因为不同类型数据的量纲不同;且样本数值波动较大时,不利于模型的学习训练。为消除特征向量间的量纲影响、保证模型运行速度以及提高预测精度,需对训练样本数值进行归一化处理。归一化公式见式(14)。
x ' = x - m i n ( x ) m a x ( x ) - m i n ( x ) (14)
式中,x m a x ( x ) m i n ( x ) x '
3.2 算法流程
步骤1:将经过预处理后的n 组水质样本数据( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n )
步骤2:对GNFA算法参数进行初始化设置,包括萤火虫数量M 、初始吸引度β 0 γ 、步长因子上下限α m a x α m i n T 。
步骤3:[ c , σ ] { y ̂ i , … , y ̂ n }
步骤4:将预测值与实际值的均方根误差作为GNFA-SVR算法的适应度。
步骤5:判断终止条件,即当前迭代次数是否大于设置的最大迭代次数;满足终止条件执行步骤7,不满足则执行下一步骤。
步骤6:根据萤火虫的相对亮度决定下一个位置的移动方向并调整步长α [ c , σ ]
步骤7:将输出的最优解[c * , σ *
3.3 污水厂出水TN预测
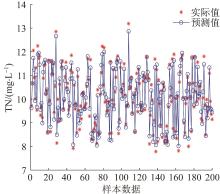
设置模型参数:萤火虫数目M =40,光强吸收系数γ =1.0,初始吸引度β 0 =0.8,步长因子α max =0.8、α min =0.1,最大迭代次数T =600,α 变化停止阈值Th =10-3 ,惩罚因子c 取值范围为[0.01,1 000],σ 取值范围为[0.001,10]。在MATLAB R2018b环境下借助支持向量回归机工具箱运行GNFA-SVR模型。基于GNFA-SVR模型对测试集的出水TN预测结果见图5 ,GNFA-SVR可以较好地预测出水TN的实际值,预测误差较小。
图5
图5
出水TN预测结果
Fig. 5
Prediction results of total nitrogen in effluent
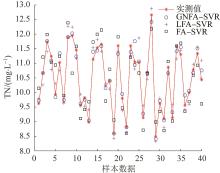
为进一步验证3种算法在实际问题上对SVR算法的优化效果,现用GNFA-SVR、LFA-SVR和FA-SVR这3种预测算法对出水TN进行预测。部分测试样本的预测结果见图6 ,其中GNFA-SVR与LFA-SVR的模型参数设置同上;FA-SVR所需参数步长α =0.4,其他参数和GNFA-SVR算法设置一致。
图6
图6
出水TN预测结果对比
Fig. 6
Comparison of predicted results of TN in effluent
从3种模型预测对比图(图6 )可看出,3种模型的预测值与实测值的变化趋势基本一致,其中GNFA-SVR模型预测值与实测值拟合效果最佳,预测误差最小。
对3种模型的性能进行具体评估,采用平均绝对误差(MAE)、最大误差(Maxer)和均方根误差(RMSE)对预测结果进行评定,表达式见式(15)~(17)。
M A E = 1 N ∑ i = 1 N | ( y ̂ i - y i ) | (15)
M a x e r = m a x y i - y ̂ i (16)
R M S E = 1 N ∑ i = 1 N y i - y ̂ i 2 (17)
式中,N 为样本总个数;y ̂ i y i
由表4 可知,GNFA-SVR算法预测结果的各项指标均优于其他2种算法,其中MAE为0.352 1,预测误差控制在±0.5 mg/L以内可满足污水厂实际生产需求;RMSE较LFA-SVR算法与FA-SVR算法分别降低了29.7%、63.2%。说明GNFA-SVR组合模型在改进策略的优化下预测性能有所提升,可实现对出水TN的精准预测。
4 结论
针对污水处理厂出水水质检测存在大滞后性的问题,本研究提出一种基于GNFA-SVR算法的预测模型。在SVR算法基础上,引入萤火虫算法对其进行参数寻优。针对标准FA算法的步长不随迭代次数变化、易出现陷入局部最优的现象,提出基于高斯函数非线性递减步长策略,有效提高了算法的性能。通过对污水处理厂的实际数据进行仿真验证,GNFA-SVR算法在平均绝对误差、最大误差和均方根误差3个评价指标方面均明显优于LFA-SVR与FA-SVR算法,预测精度最高,误差控制在±0.5 mg/L以内,可实现对出水TN的精准预测,在实际水质预测方面具有良好的应用前景。
参考文献
View Option
[1]
[本文引用: 1]
LI Haihua Zhengyang E SHI Zhentao et al Research on the upgrading process of a sewage treatment plant in Henan Province based on total nitrogen compliance
[J]. Technology of Water Treatment ,2021 ,47 (4 ):137 -140 . doi:10.16796/j.cnki.1000-3770.2021.04.028
[本文引用: 1]
[2]
DJANDJA O S DUAN Peigao YIN Linxin et al A novel machine learning-based approach for prediction of nitrogen content in hydrochar from hydrothermal carbonization of sewage sludge
[J]. Energy ,2021 ,232 :121010 . doi:10.1016/j.energy.2021.121010
[本文引用: 1]
[5]
PANAHI M GAYEN A POURGHASEMI H R et al Spatial prediction of landslide susceptibility using hybrid support vector regression(SVR) and the adaptive neuro-fuzzy inference system(ANFIS) with various metaheuristic algorithms
[J]. Science of the Total Environment ,2020 ,741 :139937 . doi:10.1016/j.scitotenv.2020.139937
[本文引用: 1]
[6]
张振全 ,李醒飞 ,杨少波 基于AR-SVR模型的有效波高短期预测
[J]. 太阳能学报 ,2021 ,42 (7 ):15 -20 .
ZHANG Zhenquan LI Xingfei YANG Shaobo Short-term prediction of significant wave height based on AR-SVR model
[J]. Acta Energiae Solaris Sinica ,2021 ,42 (7 ):15 -20 .
[7]
董栅 改进支持向量机回归的风电场功率预测
[D]. 天津 :河北工业大学 ,2018 .
DONG Shan Wind farm power prediction with support vector machine regression
[D]. Tianjin :Hebei University of Technology ,2018 .
[8]
Wang LÜ RAO Yuan ZHU Jun Design and implementation of fresh vegetable sales volume trend forecasting system based on improved SVR
[J]. Agricultural Biotechnology ,2021 (4 ):98 -103 .
[本文引用: 1]
[9]
王瑞 ,陈诗雯 ,逯静 基于模糊聚类的BOA-SVR分时段精细化短期负荷预测
[J]. 武汉大学学报:工学版 ,2021 ,54 (12 ):1140 -1149 .
[本文引用: 1]
WANG Rui CHEN Shiwen LU Jing Time-division refined short-term load forecasting based on BOA-SVR and fuzzy clustering
[J]. Engineering Journal of Wuhan University ,2021 ,54 (12 ):1140 -1149 .
[本文引用: 1]
[10]
ABDOLLAHPOUR S KOSARI-MOGHADDAM A BANNAYAN M Prediction of wheat moisture content at harvest time through ANN and SVR modeling techniques
[J]. Information Processing in Agriculture ,2020 ,7 (4 ):500 -510 . doi:10.1016/j.inpa.2020.01.003
[本文引用: 1]
[11]
张运厚 ,李婉莹 ,董福贵 基于DE-GWO-SVR的中长期电力需求预测
[J]. 中国电力 ,2021 ,54 (9 ):83 -88 .
[本文引用: 1]
ZHANG Yunhou LI Wanying DONG Fugui Medium and long-term power demand forecasting based on DE-GWO-SVR
[J]. Electric Power ,2021 ,54 (9 ):83 -88 .
[本文引用: 1]
[12]
施瑶 ,陈昭 基于SAFA优化LSSVM的粮食产量预测
[J]. 中国农机化学报 ,2019 ,40 (3 ):144 -148 .
[本文引用: 1]
SHI Yao CHEN Zhao Prediction of grain yield based on LSSVM optimized by SAFA
[J]. Journal of Chinese Agricultural Mechanization ,2019 ,40 (3 ):144 -148 .
[本文引用: 1]
[13]
SAYARI S MAHDAVI-MEYMAND A ZOUNEMAT-KERMANI M Irrigation water infiltration modeling using machine learning
[J]. Computers and Electronics in Agriculture ,2021 ,180 :105921 . doi:10.1016/j.compag.2020.105921
[本文引用: 1]
[14]
NAND R SHARMA B N CHAUDHARY K Stepping ahead firefly algorithm and hybridization with evolution strategy for global optimization problems
[J]. Applied Soft Computing ,2021 ,109 :107517 . doi:10.1016/j.asoc.2021.107517
[本文引用: 1]
[15]
陈文平 多策略分层学习萤火虫算法研究及应用
[D]. 南昌 :南昌工程学院 ,2020 .
[本文引用: 1]
CHEN Wenping Research and application of firefly algorithm based on multi-strategy and level-based learning
[D]. Nanchang :Nanchang Institute of Technology ,2020 .
[本文引用: 1]
[16]
唐宏 ,冯平 ,陈镜伯 ,等 萤火虫算法优化SVR参数在短期电力负荷预测中的应用
[J]. 西华大学学报:自然科学版 ,2017 ,36 (1 ):35 -38 .
[本文引用: 1]
TANG Hong FENG Ping CHEN Jingbo et al Application of firefly algorithm-based optimization of SVR parameters in short-term power load forecasting
[J]. Journal of Xihua University:Natural Science Edition ,2017 ,36 (1 ):35 -38 .
[本文引用: 1]
[17]
QASIM O S NOORI N M A new hybrid algorithm based on binary gray wolf optimization and firefly algorithm for features selection
[J]. Asian-European Journal of Mathematics ,2021 ,14 (10 ):2150172 . doi:10.1142/s1793557121501722
[本文引用: 1]
[18]
EBERHART R C SHI Yuhui Particle swarm optimization:Developments,applications and resources
[J]. Proceedings of the 2001 Congress on Evolutionary Computation(IEEE Cat. No . 01 TH8546),2001,1 :81 -86 .
[本文引用: 1]
[19]
张丽娜 萤火虫算法研究及其在船舶运动参数辨识中的应用
[D]. 哈尔滨 :哈尔滨工程大学 ,2017 .
[本文引用: 1]
ZHANG Li’na Research on firefly algorithm and its application in parameter identification of ship motions
[D]. Harbin :Harbin Engineering University ,2017 .
[本文引用: 1]
基于总氮达标的河南省某污水处理厂提标改造工艺研究
1
2021
... 氮是微生物繁殖的必要元素,但也是引发水体富营养化的元素之一〔1 〕 .出水总氮(TN)是污水排放的重要指标之一,当出水TN检测结果不达标时,污水厂会采取应急措施,通过调整某个工艺段的工艺参数来解决问题.因此,根据实时进水水质情况判断未来出水TN是否存在超标可能并提前对工艺参数进行调整,对污水处理系统的优化具有重要意义. ...
基于总氮达标的河南省某污水处理厂提标改造工艺研究
1
2021
... 氮是微生物繁殖的必要元素,但也是引发水体富营养化的元素之一〔1 〕 .出水总氮(TN)是污水排放的重要指标之一,当出水TN检测结果不达标时,污水厂会采取应急措施,通过调整某个工艺段的工艺参数来解决问题.因此,根据实时进水水质情况判断未来出水TN是否存在超标可能并提前对工艺参数进行调整,对污水处理系统的优化具有重要意义. ...
A novel machine learning-based approach for prediction of nitrogen content in hydrochar from hydrothermal carbonization of sewage sludge
1
2021
... 在污水水质预测创建模型方面,众多学者从污水处理过程机理和数据驱动方式去构建模型.O. S. DJANDJA等〔2 〕 提出一种根据生化反应温度与原料中元素含量关系的前馈神经网络氮含量预测模型.乔俊飞等〔3 〕 采用一种基于递归径向基(RBF)神经网络算法的氨氮软测量方法.尽管神经网络算法在预测领域有着不错的性能表现,但也存在一定局限性,如收敛速度慢、易陷入局部极值、过度拟合等〔4 〕 . ...
基于递归RBF神经网络的出水氨氮预测研究
1
2017
... 在污水水质预测创建模型方面,众多学者从污水处理过程机理和数据驱动方式去构建模型.O. S. DJANDJA等〔2 〕 提出一种根据生化反应温度与原料中元素含量关系的前馈神经网络氮含量预测模型.乔俊飞等〔3 〕 采用一种基于递归径向基(RBF)神经网络算法的氨氮软测量方法.尽管神经网络算法在预测领域有着不错的性能表现,但也存在一定局限性,如收敛速度慢、易陷入局部极值、过度拟合等〔4 〕 . ...
基于递归RBF神经网络的出水氨氮预测研究
1
2017
... 在污水水质预测创建模型方面,众多学者从污水处理过程机理和数据驱动方式去构建模型.O. S. DJANDJA等〔2 〕 提出一种根据生化反应温度与原料中元素含量关系的前馈神经网络氮含量预测模型.乔俊飞等〔3 〕 采用一种基于递归径向基(RBF)神经网络算法的氨氮软测量方法.尽管神经网络算法在预测领域有着不错的性能表现,但也存在一定局限性,如收敛速度慢、易陷入局部极值、过度拟合等〔4 〕 . ...
基于改进粒子群优化LSSVM的污水COD软测量建模
1
2021
... 在污水水质预测创建模型方面,众多学者从污水处理过程机理和数据驱动方式去构建模型.O. S. DJANDJA等〔2 〕 提出一种根据生化反应温度与原料中元素含量关系的前馈神经网络氮含量预测模型.乔俊飞等〔3 〕 采用一种基于递归径向基(RBF)神经网络算法的氨氮软测量方法.尽管神经网络算法在预测领域有着不错的性能表现,但也存在一定局限性,如收敛速度慢、易陷入局部极值、过度拟合等〔4 〕 . ...
基于改进粒子群优化LSSVM的污水COD软测量建模
1
2021
... 在污水水质预测创建模型方面,众多学者从污水处理过程机理和数据驱动方式去构建模型.O. S. DJANDJA等〔2 〕 提出一种根据生化反应温度与原料中元素含量关系的前馈神经网络氮含量预测模型.乔俊飞等〔3 〕 采用一种基于递归径向基(RBF)神经网络算法的氨氮软测量方法.尽管神经网络算法在预测领域有着不错的性能表现,但也存在一定局限性,如收敛速度慢、易陷入局部极值、过度拟合等〔4 〕 . ...
Spatial prediction of landslide susceptibility using hybrid support vector regression(SVR) and the adaptive neuro-fuzzy inference system(ANFIS) with various metaheuristic algorithms
1
2020
... 与神经网络算法相比,支持向量回归机(SVR)具有训练时间短、泛化能力强、预测精度高的优点,并且克服了神经网络算法在小样本、非线性问题中的重复性差、过度拟合等不足,更适用于预测研究〔5 -8 〕 .然而,SVR模型构建的关键是解决核参数σ 和惩罚因子c 的最优取值问题,初期算法的参数选取多依赖于主观经验,缺乏严谨的数学依据.本研究通过引入基于高斯函数递减步长的萤火虫算法(GNFA)对SVR参数进行优化,可有效提高模型的预测准确度. ...
基于AR-SVR模型的有效波高短期预测
0
2021
基于AR-SVR模型的有效波高短期预测
0
2021
Design and implementation of fresh vegetable sales volume trend forecasting system based on improved SVR
1
2021
... 与神经网络算法相比,支持向量回归机(SVR)具有训练时间短、泛化能力强、预测精度高的优点,并且克服了神经网络算法在小样本、非线性问题中的重复性差、过度拟合等不足,更适用于预测研究〔5 -8 〕 .然而,SVR模型构建的关键是解决核参数σ 和惩罚因子c 的最优取值问题,初期算法的参数选取多依赖于主观经验,缺乏严谨的数学依据.本研究通过引入基于高斯函数递减步长的萤火虫算法(GNFA)对SVR参数进行优化,可有效提高模型的预测准确度. ...
基于模糊聚类的BOA-SVR分时段精细化短期负荷预测
1
2021
... 支持向量回归机(SVR)是一种监督性机器学习算法,是在支持向量机(SVM)理论基础上延伸出的一种对回归分析问题的应用模型.SVR通过引入不敏感损失系数ε 让所有的样本点与超平面距离和最小,得到一个最佳条状区域(2ε 宽度),以达到期望风险最小的目的〔9 〕 . ...
基于模糊聚类的BOA-SVR分时段精细化短期负荷预测
1
2021
... 支持向量回归机(SVR)是一种监督性机器学习算法,是在支持向量机(SVM)理论基础上延伸出的一种对回归分析问题的应用模型.SVR通过引入不敏感损失系数ε 让所有的样本点与超平面距离和最小,得到一个最佳条状区域(2ε 宽度),以达到期望风险最小的目的〔9 〕 . ...
Prediction of wheat moisture content at harvest time through ANN and SVR modeling techniques
1
2020
... 引入不敏感损失系数ε 与惩罚因子c ,y i f ( x i ) y i f ( x i ) ε 时计算损失;反之则认为预测正确,不计算损失〔10 〕 .不敏感损失系数ε 对模型影响较小,选取0.15即可.根据最小结构风险原则,建立约束条件〔式(2) 〕与目标函数〔式(3) 〕. ...
基于DE-GWO-SVR的中长期电力需求预测
1
2021
... 惩罚因子c 的取值影响模型的结构风险,取值过大,结构风险越大,模型容易出现过拟合;取值过小,模型会过于简单化,易出现欠拟合问题〔11 〕 . ...
基于DE-GWO-SVR的中长期电力需求预测
1
2021
... 惩罚因子c 的取值影响模型的结构风险,取值过大,结构风险越大,模型容易出现过拟合;取值过小,模型会过于简单化,易出现欠拟合问题〔11 〕 . ...
基于SAFA优化LSSVM的粮食产量预测
1
2019
... 萤火虫算法(FA)是一种启发式算法,是根据自然界中萤火虫的发光行为提出的〔12 〕 .在FA中,空间里的每一个解就好比萤火虫种群里的每一只萤火虫,空间里的初始解可以理解为萤火虫种群的初始位置,萤火虫通过个体之间的吸引进行移动,完成位置的更新,即完成解的更新〔13 〕 . ...
基于SAFA优化LSSVM的粮食产量预测
1
2019
... 萤火虫算法(FA)是一种启发式算法,是根据自然界中萤火虫的发光行为提出的〔12 〕 .在FA中,空间里的每一个解就好比萤火虫种群里的每一只萤火虫,空间里的初始解可以理解为萤火虫种群的初始位置,萤火虫通过个体之间的吸引进行移动,完成位置的更新,即完成解的更新〔13 〕 . ...
Irrigation water infiltration modeling using machine learning
1
2021
... 萤火虫算法(FA)是一种启发式算法,是根据自然界中萤火虫的发光行为提出的〔12 〕 .在FA中,空间里的每一个解就好比萤火虫种群里的每一只萤火虫,空间里的初始解可以理解为萤火虫种群的初始位置,萤火虫通过个体之间的吸引进行移动,完成位置的更新,即完成解的更新〔13 〕 . ...
Stepping ahead firefly algorithm and hybridization with evolution strategy for global optimization problems
1
2021
... 搜索过程涉及到萤火虫的发光亮度和相互吸引度〔14 〕 ,这2个参数都与萤火虫之间的距离成反比,这与自然现象中光在空间传播时被传播介质吸收而逐渐衰减的特性一致. ...
多策略分层学习萤火虫算法研究及应用
1
2020
... 式中,I r r i j i j r i j = | | X i - X j | | γ 的改变可以理解为传播介质的改变,可设置为常数;当萤火虫个体与光源的距离逐渐趋近于0时,萤火虫的发光亮度最为明亮,即为I 0 〔15 〕 . ...
多策略分层学习萤火虫算法研究及应用
1
2020
... 式中,I r r i j i j r i j = | | X i - X j | | γ 的改变可以理解为传播介质的改变,可设置为常数;当萤火虫个体与光源的距离逐渐趋近于0时,萤火虫的发光亮度最为明亮,即为I 0 〔15 〕 . ...
萤火虫算法优化SVR参数在短期电力负荷预测中的应用
1
2017
... 萤火虫的吸引度β 式(9) ,与萤火虫发光强度同理,当萤火虫个体与光源的距离逐渐趋近于0时,吸引度最大,即为β 0 〔16 〕 . ...
萤火虫算法优化SVR参数在短期电力负荷预测中的应用
1
2017
... 萤火虫的吸引度β 式(9) ,与萤火虫发光强度同理,当萤火虫个体与光源的距离逐渐趋近于0时,吸引度最大,即为β 0 〔16 〕 . ...
A new hybrid algorithm based on binary gray wolf optimization and firefly algorithm for features selection
1
2021
... 式中,X i ' α ( r a n d - 0.5 ) α r a n d 〔17 〕 . ...
Particle swarm optimization:Developments,applications and resources
1
01
... 在文献〔18 〕中,优化粒子群算法引入了线性递减权重.受该思路启发,不妨将萤火虫的步长进行线性递减优化,定义该种改进算法为线性递减步长萤火虫算法(LFA),具体步长变化表达式见式(11) . ...
萤火虫算法研究及其在船舶运动参数辨识中的应用
1
2017
... 为验证改进算法的性能,分别将FA、LFA与提出的GNFA进行比较.选择Sphere函数和Ackley函数作为测试算法性能的函数,Sphere函数多用来检验算法的收敛速度和精度,Ackley函数可以测试算法的局部寻优能力.这2个函数是最常见的测试函数,被广泛应用在算法测试性能实验中〔19 〕 . ...
萤火虫算法研究及其在船舶运动参数辨识中的应用
1
2017
... 为验证改进算法的性能,分别将FA、LFA与提出的GNFA进行比较.选择Sphere函数和Ackley函数作为测试算法性能的函数,Sphere函数多用来检验算法的收敛速度和精度,Ackley函数可以测试算法的局部寻优能力.这2个函数是最常见的测试函数,被广泛应用在算法测试性能实验中〔19 〕 . ...





 津公网安备 12010602120337号
津公网安备 12010602120337号{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}